Generating Synthetic Data
Quick Summary
Manually generating test data is time-consuming and can be non-comprehensive), so we’ll be generating synthetic data to test our medical chatbot. This data should mimic your user's interaction with your LLM application, from typical usage behavior to unique test cases.
DeepEval's synthesizer offers a fast and easy way to generate high-quality goldens (input, expected output, context) for your evaluation datasets in just a few lines of code. We'll be using 2 to generate our test data.
- Generating from Documents
- Generating from Scratch
DeepEval also allows you to generate directly from contexts, but since we don't have access to pre-prepared contexts and only our knowledge base, we'll be generating from documents intead.
Synthetic Data Generation Methods
From Documents
Generating synthetic data from documents invovles extracting contexts from your knowledge base and generating synthetic data based on these contexts. This will be especially helpful in testing our RAG engine when medical diagnoses are being performed.
From Scratch
We'll generate synthetic data from scratch to test non-RAG parts of our LLM application, like filling in user emails and information, and handling non-diagnosis-related queries.
If you haven't already, log in to Confident AI with your Confident AI key by running the following command in your CLI. We'll be reviewing the dataset on the platform in this tutorial.
deepeval login
Generating Synthetic Data from Documents
1. Defining Style Configuration
DeepEval allows you to customize the output style and format of any input and/or expected_output. You can achieve this by creating an instance of the Synthesizer with specific StylingConfig settings.
from deepeval.synthesizer.config import StylingConfig
styling_config = StylingConfig(
expected_output="Ensure the output resembles a medical chatbot tasked with diagnosing a patient’s illness. It should pose additional questions if the details are inadequate or provide a diagnosis when the input is sufficiently detailed.",
input_format="Mimic the kind of queries or statements a patient might share with a medical chatbot when seeking a diagnosis.",
task="The chatbot acts as a specialist in medical diagnosis, integrated with a patient scheduling system. It manages tasks in a sequence to ensure precise and effective appointment setting and diagnosis processing.",
scenario="Non-medical patients describing symptoms to seek a diagnosis.",
)
Given that our knowledge base is essentially a collection of medical data, we need to ensure that the inputs accurately reflect individuals seeking medical diagnosis.
We'll also need to align our expected output with our LLM's expected behaviour, namely providing correct diagnoses based on the symptoms presented or asking for clarifying symptoms.
2. Defining Context Construct Configuration
When generating goldens from documents, the default max_contexts_per_document is set to 3. However, given our extensive knowledge base, we’ll need to generate significantly more goldens. Fortunately, Deepeval allows us to adjust this configuration through the ContextConstructionConfig object.
from deepeval.synthesizer.config import ContextConstructionConfig
context_config = ContextConstructionConfig(
max_contexts_per_document=10
)
This configuration also enables you to specify a custom critic_model, define chunking parameters such as chunk_size and chunk_overlap, and control content quality through pre-set filters.
3. Goldens generation
With our configurations defined, let’s finally begin generating synthetic goldens. You can generate as many goldens_per_context as you’d like. For this tutorial, we’ll set this parameter to 2, as coverage across different contexts is more important.
We'll be generating our goldens through DeepEval's EvaluationDataset, but this can also be accomplished with the Synthesizer directly.
dataset=EvaluationDataset()
dataset.generate_goldens_from_docs(
max_goldens_per_context=2,
document_paths=["./synthesizer_data/encyclopedia.pdf"],
context_construction_config=context_config
)
4. Pushing Dataset
Next, we’ll be pushing the dataset to Confident AI so you can review your dataset.
dataset.pull(alias="Synthetic Test")
5. Reviewing Dataset
You can easily review synthetically generated datasets on Confident AI. This is especially important for teams, particularly when non-technical team members—such as domain experts or human reviewers—are involved. To get started, simply navigate to the datasets page on the platform and select the dataset you uploaded.
Confident AI enables project collaborators to edit each golden directly on the platform, including inputs, actual outputs, retrieval context, and more.
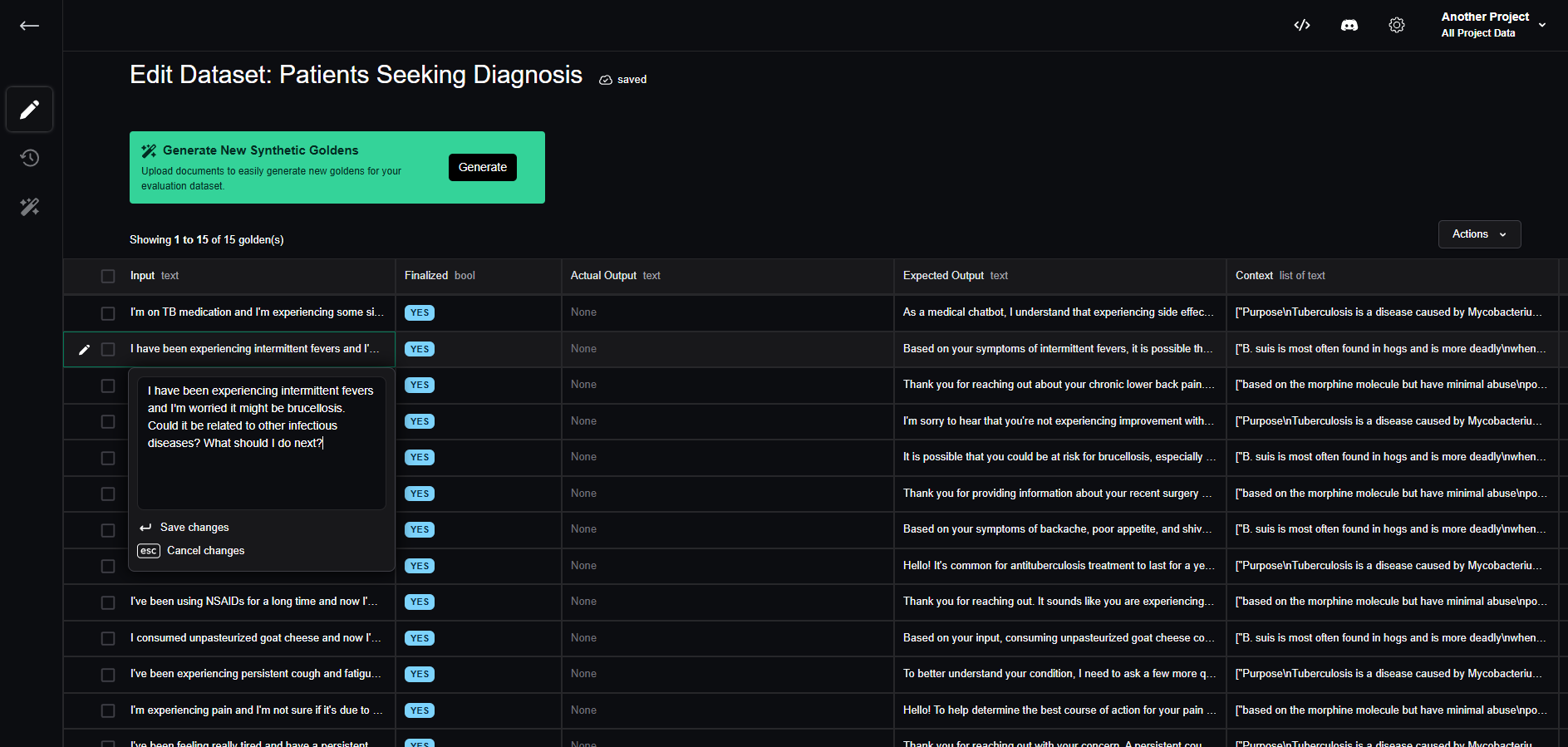
You can also leave comments for other team members or push comments directly from your code. Lastly, you have the option to toggle finalization for each golden, streamlining the review process.
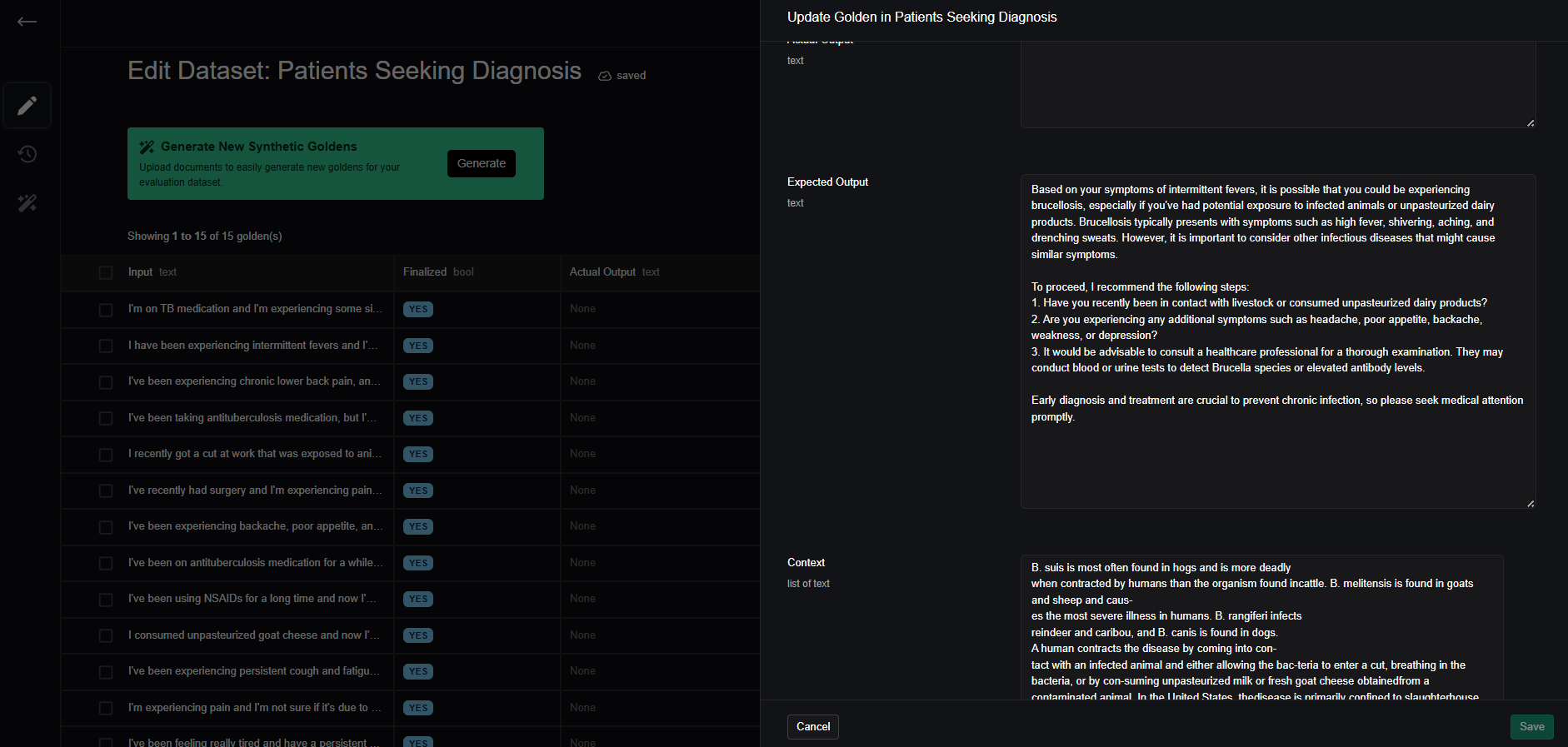
Once dataset review is complete, engineers can easily pull the entire dataset within a single line of code and begin the evaluation process.
dataset.pull(alias="Synthetic Test")
6. Exploring Additional Generation Configurations
You may want to explore additional styling or quality configurations for your dataset generation. This allows you to create a dataset that is diverse and include edge cases.
Ambiguous Inputs
For example, you may want to generate synthetic goldens where the user input describes borderline symptoms—sufficient to narrow down the options but not enough to make a definitive diagnosis without asking additional clarifying questions. This helps evaluate how your medical chatbot handles such ambiguous inputs.
styling_config_ambiguous = StylingConfig(
expected_output="Provide a cautious and detailed response to borderline or ambiguous symptoms. The chatbot should ask clarifying questions when necessary to avoid making unsupported conclusions.",
input_format="Simulate user inputs that describe borderline symptoms, where the details are vague or insufficient for a definitive diagnosis.",
task="The chatbot acts as a specialist in medical diagnosis, integrated with a patient scheduling system. It manages tasks in a sequence to ensure precise and effective appointment setting and diagnosis processing.",
scenario="Non-medical patients describing symptoms that are vague or ambiguous, requiring further clarification from the chatbot."
)
In medical use cases, false positives are generally preferred over false negatives. It's essential to consider your specific use case and the expected behavior of your LLM application when exploring different styling configurations.
Challenging User Scenarios
In another scenario, you may want to test how your chatbot reacts to users who are rude or in a hurry. This allows you to evaluate its ability to maintain professionalism and provide effective responses under challenging circumstances. Below is an example styling configuration:
styling_config_challenging = StylingConfig(
expected_output="Respond politely and remain professional, even when the user is rude or impatient. The chatbot should maintain a calm and empathetic tone while providing clear and actionable advice.",
input_format="Simulate users being rushed, frustrated, or disrespectful in their queries.",
task="The chatbot acts as a specialist in medical diagnosis, integrated with a patient scheduling system. It manages tasks in a sequence to ensure precise and effective appointment setting and diagnosis processing.",
scenario="Users who are impatient, stressed, or rude but require medical assistance and advice."
)
High Quality Configurations
For high-priority use cases, you may want to define higher-quality filters to ensure that the generated dataset meets rigorous standards. While this approach might cost more to generate the same number of goldens, the trade-off can be invaluable for critical applications. Here’s an example of how you can define such quality filters:
from deepeval.synthesizer.config import FiltrationConfig
from deepeval.synthesizer import Synthesizer
filtration_config = FiltrationConfig(
critic_model="gpt-4o", # Model used to assess the quality of generated data
synthetic_input_quality_threshold=0.8 # Minimum acceptable quality score for generated inputs
)
synthesizer = Synthesizer(filtration_config=filtration_config)
You might want to push different evaluation datasets for various configurations to the platform. To do so, simply push the new dataset under a different name:
dataest.push(alias="Ambiguous Synthetic Test")
Generating Synthetic Data from Scratch
1. Defining Style Configuration
Similar to generating from documents, you'll want to customize the output style and format of any input and/or expected_output when generating synthetic goldens from scratch. When generating from scratch, your creativity is your limit. You can test your LLM for any interaction you can foresee. In the example below, we'll define user inputs to try to book an appointment by providing name information and email.
from deepeval.synthesizer.config import StylingConfig
styling_config = StylingConfig(
input_format="User inputs including name and email information for appointment booking.",
expected_output_format="Structured chatbot response to confirm appointment details.",
task="The chatbot acts as a specialist in medical diagnosis, integrated with a patient scheduling system. It manages tasks in a sequence to ensure precise and effective appointment setting and diagnosis processing.",
scenario="Non-medical patients describing symptoms to seek a diagnosis."
)
Alternatively, you can also just make the patient say a greeting to the chatbot.
styling_config = StylingConfig(
input_format="Simple greeting from the user to start interaction with the chatbot.",
expected_output_format="Chatbot's friendly acknowledgment and readiness to assist.",
task="The chatbot acts as a specialist in medical diagnosis, integrated with a patient scheduling system. It manages tasks in a sequence to ensure precise and effective appointment setting and diagnosis processing.",
scenario="A patient greeting the chatbot to initiate an interaction."
)
2. Generating the Goldens
The next step is to simply initialize your synthesizer with the styling configurations and push the dataset to Confident AI for review.
from deepeval.synthesizer import Synthesizer
# Initialize synthesizer for appointment booking
synthesizer = Synthesizer(styling_config=styling_config)
synthesizer.generate_goldens_from_scratch(num_goldens=25)
dataset.push("Synthetic Test from Scratch")
The reason why the expected output format works better than relying on your LLM directly is that it is hyper-focused on one task or topic. In contrast, a typical LLM application operates with a longer system prompt and may even be fine-tuned, making it less focused on handling very specific queries with precision.